


如今想要在搜索引擎中拥有良好排名,就需要具有完美SEO基础的网站。如果您还想充分利用自己的网站并继续保持领先地位,则必须具备一些SEO技术的基本知识。今天我们将解释SEO技术的最重要概念之一:可爬行性。
爬行器是什么?
一般来说,我们把搜索引擎用来爬行和访问页面的程序称作爬行器(或者称为蜘蛛(spider)、爬虫、机器人等),通常由搜寻器,索引和算法组成。搜寻器追踪链接,找到您的网站后,便会读取该网站并将其内容保存在索引中。
搜寻器会追踪网络上的链接,它7*24小时全天候在线。进入网站后,它会将页面的HTML版本保存在一个巨大的数据库中,称为索引。每当搜寻器访问您的网站并发现它的新版本或修订版本时,此索引都会更新。这个更新速度就取决于搜索引擎对您的网站的重视程度以及您在网站上所做的更改数量了。
什么是可爬行性?
可爬行性与搜索引擎抓取您的网站的可能性有关,爬网程序可能会被阻止访问您的网站。有几种方法可以阻止爬行程序进入您的网站。如果您的网站或网站页面被阻止,则是对搜索引擎的抓取工具说:“不要来这里”。在大多数情况下,您的网站或相应页面就不会出现在搜索结果中。
以下就是阻止搜索引擎抓取网站的常用方法:
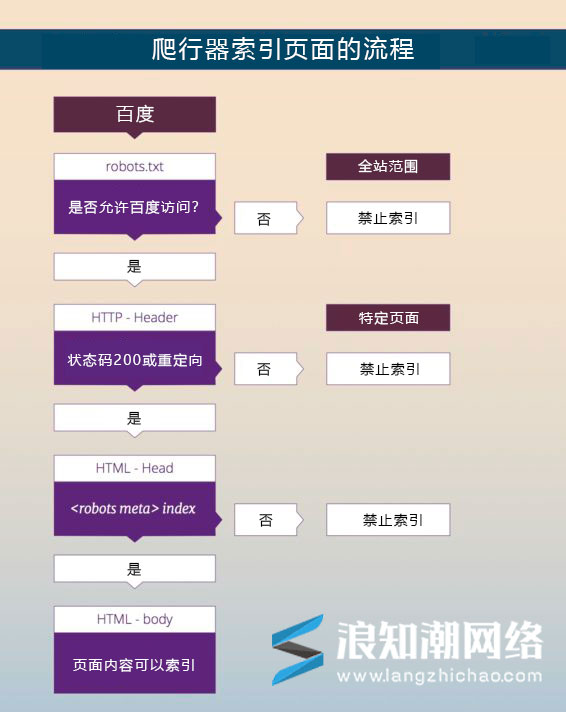
- 如果您的robots.txt文件阻止了该抓取工具,则搜索引擎不会访问您的网站或特定网页。
- 在搜寻您的网站之前,搜寻器将查看您页面的HTTP标头。此HTTP标头包含状态码。如果此状态码表明页面不存在,则搜索引擎不会抓取您的网站。
- 如果特定页面上的robots元标记阻止了搜索引擎对该页面建立索引,则搜索引擎会对该页面进行爬行,但不会将其添加到其索引中。
此流程图可能有助于您了解爬行器在尝试索引页面时遵循的流程:
是否想全面了解可爬行性?
尽管可爬行性只是SEO的基本知识,但对于大多数人来说,它已经是相当复杂的东西了。不过,如果因您不了解可爬行性而意外阻止了搜索引擎访问,您将永远不会在搜索引擎中获得排名。因此如果有什么不了解的您可以在线咨询我们的客服。
如果您真的想了解有关可爬行性的所有技术方面,则绝对应该查看我们的SEO顾问服务。在此SEO服务中,我们将教您如何检测SEO技术性问题以及如何解决它们。

